파일 시스템은 100퍼센트 소프트웨어 프로그램이다. 이는 단지 더 잘 실행될 수 있기 위해 하드웨어의 기능을 추가하지 않았다.
1. Data structures
아래 그림은 파일 시스템의 데이터 구조을 나타낸 그림이다.
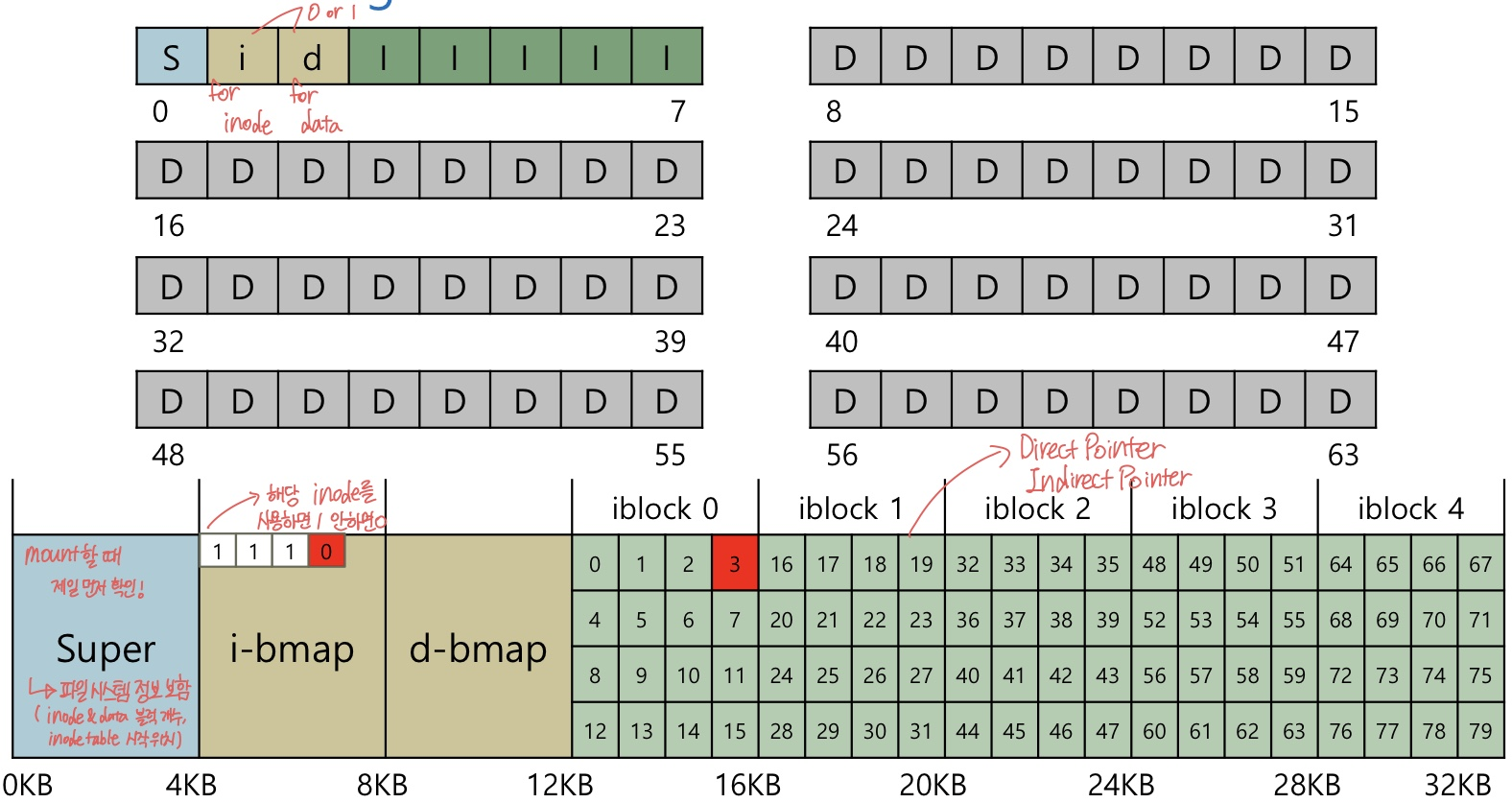
위 그림을 보며 하나하나 설명해보겠다.
1.1 Block
디스크의 단위이다.
전체적으로 데이터는 연속적은 Block으로 이루어져 있다.
위에 보면 D 가 적혀 있는 박스 하나가 한 Block이다.
1.2 Data region
이 블록들을 위해 디스크에는 고정된 부분이 있다.
이는 그림에서 D로 표현되어있으며 데이터가 저장되어있다.
1.3 Metadata
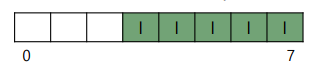
Metadata란 데이터들을 위한 데이터를 의미한다.
인덱스 3번부터 7번 까지를 보면 I 라고 되어있다. 이는 inode table이라고 부른다.
각 데이터들의 inode가 모여있다.
여기에는 각 파일에 대한 정보가 들어있다. 여기세응 어떤 데이터를 가지고 파일을 구성하는지에 대한 내용이들어있다.
예를 들어 파일 소유자, 액세스 권한, 액세스 및 수정시간 등등...
inode는 용량이 크지 않기 때문에 한 블럭에 여러개의 inode가 들어있다.
1.4 Allocation structures
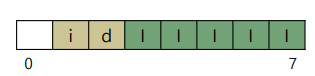
여기에는 할당이 되었는지 안되었는지에 대한 정보가 담겨있다.
맨 위에 그림의 1번 인덱스와 2번 인덱스를 보면된다.
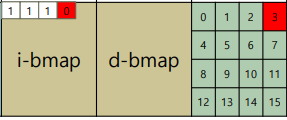
1번 인덱스는 inode table에 어디가 사용중인지 1대1 mapping 되어 나타내져 있다.
2번 인덱스에는 Data region 중 어디가 쓰여있고 어디가 안쓰였는지에 대한 내용이 담겨있다.
1.4 Superblock

인덱스 0번에는 Super block의 자리이다. 여기에는 파일 시스템에 있는 아이노드 및 데이터 블록 수, 아이노드 테이블 시작 위치 등 특정 파일 시스템에 대한 정보가 들어있다.
파일 시스템을 마운트할 때 OS는 먼저 슈퍼블록을 읽고 다양한 매개 변수를 초기화한 다음 파일 시스템 트리에 연결
1.5 Size
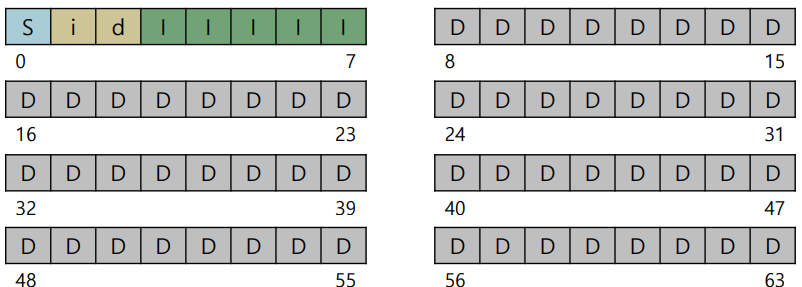
이 데이터 구조의 사이즈에 대해 알아보자.
Block size는 4 KB inode size는 256 B 라고 가정을 하면
Block 의 개수는 총 64개 임으로 총 사이즈는 256KB 가 된다.
inode는 사이즈가 256 바이트임으로 한 블록에 16개가 들어갈 수 있고 inode block 의 개수가 5개임으로 총 inode는 80개가 된다.
1.6 inode acess
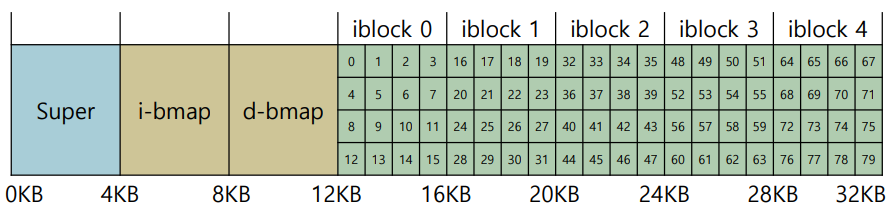
i-number 란 각 inode에 암묵적으로 참조되는 숫자이다. i-number가 주어지면 디스크에서 해당 inode의 위치를 직접 계싼할 수 있다.
예를 들어 i-number 32에 접근하려고 하면
먼저 inode table의 시작위치를 파악해야한다. 지금 경우에는 12KB 이다.
또 노드 하나에 256B 인데 그 중에 32 번 쨰 인 것이기 때문에 256B * 32 = 8KB 가 된다.
최종 i-number 32의 위치는 12KB + 8KB = 20KB가 된다.
디스크는 바이트로 주소에 접근할수 없어 섹터로 지정해줘야한다
512B 를 Sector address로 바꾸기 위해서는 아래와 같은 식을 거쳐야한다.
(20 x 1024) / 512 = 40
-> 40번 sector
하지만 그럼에도 block은 256 바이트인데 sector은 512 바이트여서 다른 블럭까지 읽게 된다.
inode는 direct pointers 와 indirect pointer를 가질 수 있다.
direct pointers는 데이터를 가르키고 indirect pointer은 direct pointers가 많이 모여있는 블록을 가르킨다.
indirect pointer은 보통 파일이 큰 경우 사용된다.
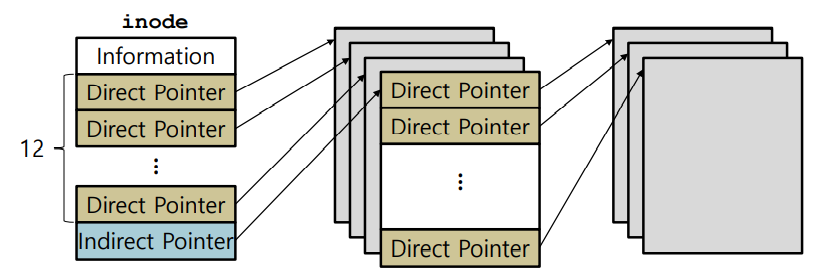
위 사진은 direct pointers 와 indirect pointer의 예시이다.
12개의 direct pointers를 가졌고 1개의 indirect pointer를 가졌다.
Block size는 4KB이며 disk address는 4B 이다.
우리는 위와같은 정보로 파일은 총 direct pointers에서 12개 indirect pointer에서 1024개(4KB / 4B) 개를 더한 1036개가 들어갈 수 있고 그러기 위해서는 파일 블록 메모리가 1036 * 4 = 4144KB 가 필요하다는 것을 알 수 있다.
1.7 Free Space Management
파일을 만들 때 inode map을 검색하며 빈자리를 찾아야한다. bata map에서도 똑같이 빈자리를 찾는다. 혹시 데이터가 많이 필요하다면 연속적으로 빈 데이터를 찾아 연결해준다.
2. Directory Organization
디렉토리는 특정한 파일의 타입이다,
즉 디렉토리도 inode를 가지고 있다. inode 안에 있는 direct pointer를 따라가보면 아래와 같은 표가 있다.

안에는 해당 디렉토리에 들어있는 파일들의 정보가 들어있다.
inum은 파일의 inum이고 reclen 에는 파일 이름의 행길이가 들어있다. 이는 4의 배수여야하며 널널하게 측정하는 편이다.
strle 에는 null을 포함한 파일 이름의 실제 길이가 적혀있다.
디렉토리 안에 파일을 삭제할 때는 inum만 0으로 바꿔주면 된다. 이렇게 되면 연결은 끊기지만 정보는 보호되어있다. 이는 나중에 포렌식으로 찾을 수 있다. 하지만 여기에 정보가 over write 되어있다면 복구할 수 없다.
3. Reading and Writing a File to Disk
3.1 Reading a File from Disk
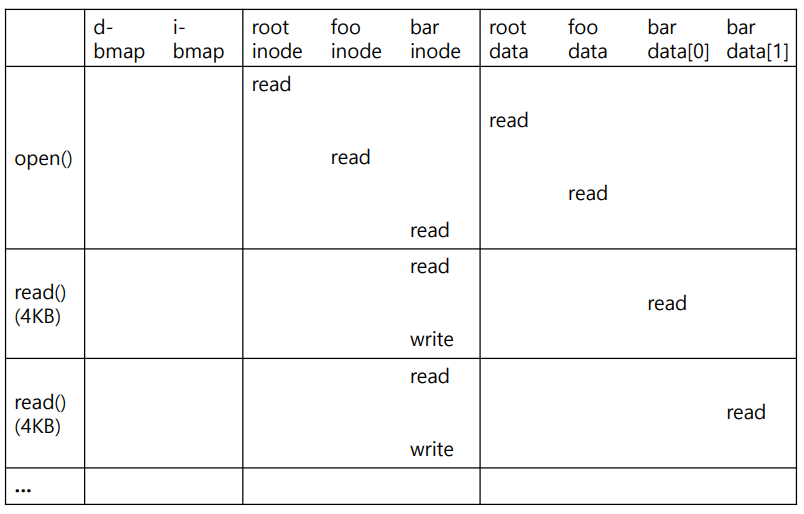
파일을 읽기 위해서는 먼저 읽고싶은 파일의 inode를 찾아야한다.
루트 -> foo -> bar 의 과정으로 접근해야한다.
먼저 루트부터 접근해야한다.
루트의 inode number은 2번으로 지정되어있다. (0은 삭제 1은 불량)
다음으로 foo의 inumber도 찾고 읽고 bar의 inode number을 찾아야한다.
bar에 접근할 준비가 되었다면 먼저 사용 권한을 검사하고 읽을 수 있다면 fd를 할당해준다.(0,1,2는 사용불가능)
fd를 읽었으니 이제는 읽을 수 있다.
read()라는 시스템콜을 사용하면 먼저 offset이 0 상태일 것이다.
또 inode 안에 마지막 액세스한 시간을 업데이트해야한다.
다 읽었다면 close()도 해줘야한다.
fd의 할당을 취소해준다.
3.2 Writing a File to Disk
작성하는 일은 읽는것에 비해 매우 복잡하다.
새로운 파일을 쓸 때는 보통 이와같은 일이 일어난다.
1. 데이터 비트맵에서 빈자리 찾기
2. 데이터 비트맵에 작성하기
3. inode 읽기
4. inode 업데이트 내용 적기
5. 실제 데이터 블럭에 쓰기
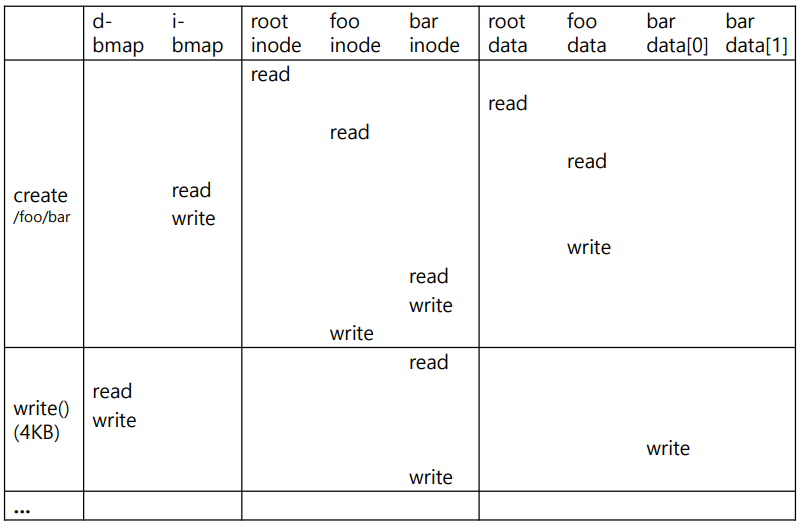
3.2 Caching and Buffering
디스크에 파일을 읽고 쓰는일은 굉장히 느리기 떄문에 성능에 영향을 많이 미친다.
따라서 버퍼캐시에 잠시 페이지 크기로 보관해 놓는다. 따라서 페이키 캐시라고도 부른다. 이른 캐시에 들어있는 것이 아닌 메로리에 있는 것이다.
데이터를 캐시에 잠시 넣어놓아 재사용을 한다.
'학부 내용 정리 > [ 2-1 ] 운영체제' 카테고리의 다른 글
| [ OS ] FSCK and Journaling (0) | 2022.06.15 |
|---|---|
| [ OS ] Files and Directories (0) | 2022.06.14 |
| [ OS ] I/O Devices and HDD (0) | 2022.06.13 |
| [ OS ] Common Concurrency Problems (0) | 2022.06.13 |
| [ OS ] Semaphores (0) | 2022.06.13 |