반응형
버전 1의 머신러닝 프로그램은 훈련 데이터 세트와 테스트 데이터 세트가 다르지 않았다.
이는 시험 보기전 답을 다 알려준 상태라고 볼 수 있다..!
테스트 세트 설정
보통은 훈련 데이터 세트에서 일부를 테스트 데이터로 활용한다.
근데 여기서 주의할 점은 훈련데이터에 한 종류의 데이터만 편향되면 안된다는 것이다.
전에 했던 데이터들을 다시 떠올려보면 도미가 35개 빙어가 14개 있었다.
여기서 도미 35개를 훈련세트로 하고 빙어 14개를 테스트세트로 하면 정확도는 0이 나올 것이다.
이를 샘플링 편향이라고 한다.
이를 방지하려면 훈련세트와 테스트세트를 잘 섞어줘야한다.
넘파이라는 라이브러리를 사용하면 이러한 작업을 편리하게 할 수 있다.
넘파이의 함수들을 사용하려면 리스트들을 넘파이배열로 바꿔줘야한다.
그런 뒤 랜덤하게 선택하여 정답과 mapping하여 훈련세트와 테스트세트를 만들면 된다.
35개의 훈련 세트와 14개의 테스트 세트를 만들어보자.
#머신러닝 프로그램 ver2
import numpy as np
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsClassifier
#도미의 정보
bream_length = [25.4, 26.3, 26.5, 29.0, 29.0, 29.7, 29.7, 30.0, 30.0, 30.7, 31.0, 31.0,
31.5, 32.0, 32.0, 32.0, 33.0, 33.0, 33.5, 33.5, 34.0, 34.0, 34.5, 35.0,
35.0, 35.0, 35.0, 36.0, 36.0, 37.0, 38.5, 38.5, 39.5, 41.0, 41.0]
bream_weight = [242.0, 290.0, 340.0, 363.0, 430.0, 450.0, 500.0, 390.0, 450.0, 500.0, 475.0, 500.0,
500.0, 340.0, 600.0, 600.0, 700.0, 700.0, 610.0, 650.0, 575.0, 685.0, 620.0, 680.0,
700.0, 725.0, 720.0, 714.0, 850.0, 1000.0, 920.0, 955.0, 925.0, 975.0, 950.0]
#빙어의 정보
smelt_length = [9.8, 10.5, 10.6, 11.0, 11.2, 11.3, 11.8, 11.8, 12.0, 12.2, 12.4, 13.0, 14.3, 15.0]
smelt_weight = [6.7, 7.5, 7.0, 9.7, 9.8, 8.7, 10.0, 9.9, 9.8, 12.2, 13.4, 12.2, 19.7, 19.9]
#머신러닝을 만들기 위한 데이터가공
length = bream_length+smelt_length
weight=bream_weight+smelt_weight
fish_data = [[l,w] for l,w in zip(length, weight)]
#정답데이터
fish_target=[1]*35 + [0]*14
#훈련세트, 테스트세트 만들기
np.random.seed(42)
input_arr=np.array(fish_data)
target_arr=np.array(fish_target)
index=np.arange(49) #0부터 48로 이루어진 배열 생성
np.random.shuffle(index) #인덱스 섞기
#앞에 35개 훈련세트로 만들기
train_input=input_arr[index[:35]]
train_target=target_arr[index[:35]]
#14개 테스트세트로 만들기
test_input=input_arr[index[35:]]
test_target=target_arr[index[35:]]
#산점도
plt.scatter(train_input[:,0],train_input[:,1])
plt.scatter(test_input[:,0],test_input[:,1])
plt.xlabel('length')
plt.ylabel('weight')
plt.show()실행시키면 아래와 같은 산점도가 나온다.
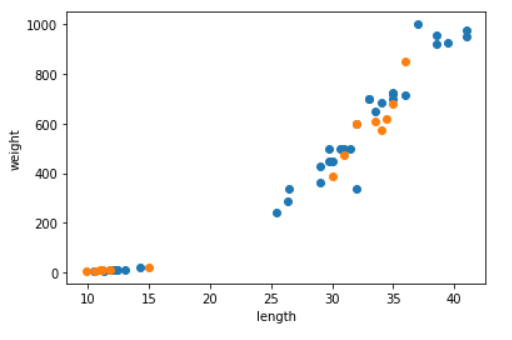
파란색이 훈련세트이고 주황색이 테스트세트이다.
아주 잘 섞여있다!
머신러닝 프로그램
이렇게 만든 훈련세트로 k최근접 이웃 모델을 테스트해보자!
kn = kn.fit(train_input,test_target)
kn.score(test_input,test_target)결과는 1이 나왔다! 정확도가 100%라는의미이다!
버전1보다 훨씬 믿음직스러운 머신러닝이 만들어졌다!
반응형
'공부 > 머신러닝' 카테고리의 다른 글
| [ 머신러닝 프로그램 ] 선형 회귀 알고리즘, 다항 회귀 알고리즘 (0) | 2023.02.17 |
|---|---|
| [ 머신러닝 프로그램 ] k최근접 이웃 회귀 알고리즘 (0) | 2023.02.13 |
| [ 머신러닝 프로그램 ] k-최근접 이웃 분류 알고리즘 ver3 - 데이터 전처리 (0) | 2023.02.13 |
| [ 머신러닝 프로그램 ] k-최근접 이웃 분류 알고리즘 ver1 (0) | 2023.02.10 |