k-최근접 이웃의 한계
k-최근접 이웃 알고리즘은 가장 가까운 샘플을 찾아 타깃을 구한다.
그렇기 때문에 새로운 샘플이 훈련 범위를 벗어나면 기대하는 값이 안나올 수도 있다.
아래 코드는 k-최근접 이웃 회귀 알고리즘 코드이다.
실제로 여기에 100kg에 농어를 넣어도, 200kg의 농어를 넣어도 가까운 농어의 종류는 똑같기 떄문에 똑같은 값이 나온다.
#k최근접 이웃 회귀 알고리즘 ver1
import matplotlib.pyplot as plt
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsRegressor
perch_length = np.array([8.4, 13.7, 15.0, 16.2, 17.4, 18.0, 18.7, 19.0, 19.6, 20.0, 21.0,
21.0, 21.0, 21.3, 22.0, 22.0, 22.0, 22.0, 22.0, 22.5, 22.5, 22.7,
23.0, 23.5, 24.0, 24.0, 24.6, 25.0, 25.6, 26.5, 27.3, 27.5, 27.5,
27.5, 28.0, 28.7, 30.0, 32.8, 34.5, 35.0, 36.5, 36.0, 37.0, 37.0,
39.0, 39.0, 39.0, 40.0, 40.0, 40.0, 40.0, 42.0, 43.0, 43.0, 43.5,
44.0])
perch_weight = np.array([5.9, 32.0, 40.0, 51.5, 70.0, 100.0, 78.0, 80.0, 85.0, 85.0, 110.0,
115.0, 125.0, 130.0, 120.0, 120.0, 130.0, 135.0, 110.0, 130.0,
150.0, 145.0, 150.0, 170.0, 225.0, 145.0, 188.0, 180.0, 197.0,
218.0, 300.0, 260.0, 265.0, 250.0, 250.0, 300.0, 320.0, 514.0,
556.0, 840.0, 685.0, 700.0, 700.0, 690.0, 900.0, 650.0, 820.0,
850.0, 900.0, 1015.0, 820.0, 1100.0, 1000.0, 1100.0, 1000.0,
1000.0])
#산점도
plt.scatter(perch_length,perch_weight)
plt.xlabel('lenght')
plt.ylabel('weight')
plt.show()
#데이터 세팅
train_input, test_input, train_target, test_target = train_test_split(perch_length, perch_weight)
train_input=train_input.reshape(-1,1)
test_input=test_input.reshape(-1,1)
#머신러닝
knr=KNeighborsRegressor();
knr.fit(train_input,train_target)
print(knr.score(train_input,train_target)) #훈련세트
print(knr.score(test_input,test_target)) #테스트세트이렇게 되면 정확하게 예측할 수가 없다!
그래서 나온 것이 선형 회귀이다.
선형 회귀
선형 회귀는 널리 사용되는 대표적인 회귀 알고리즘이다.
이는 특성이 하나인 경우에 특징이 잘 드러나는 직선을 학습하는 알고리즘이다.
직선의 위치가 훈련세트의 평균에 가깝다면 결정계수는 0에 가깝게 되고, 반대로 예측한다면 음수값이 나온다.
사이킷런은 sklearn.linear_model 패키지 아래에 LinearRegression 클래스로 알고리즘을 구현해 놓았다.
하나의 직선을 그리려면 기울기와 절편이 있어야한다.
클래스가 찾은 기울기와 절편은 객체의 coef_와 intercept_속성에 저장되어있다.
from sklearn.linear_model import LinearRegression
#선형회귀
lr=LinearRegression();
lr.fit(train_input,train_target);
#테스트
print(lr.score(train_input,train_target))
print(lr.score(test_input,test_target))훈련을 시키는 것은 어렵지 않다.
이제 훈련데이터와 테스트데이터의 결정계수를 비교해보자
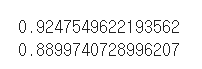
값을 비교해보면 훈련세트에 과대적합 되어있다는 것과 전체적으로 점수가 낮다는 것을 알 수 있다.

그리고 왼쪽 아래가 직선과 잘 맞지 않다는 것을 알 수 있다.
또 무게가 곧 음수로 가게될 것이라는 것도 알 수 있다.
다항 회귀
산점도를 실제 확인해보면 그냥 직선보다는 곡선에 가까운 양상을 보인다.
곡선의 모양을 구하기 위해서는 길이의 제곱한 값이 항의 훈련세트에 추가되어야한다.
훈련을 시킬때 길이와 길이를 제곱한 값을 가지고 있는 데이터와 길이 타겟 데이터를 입력해줘야한다.
train_poly = np.column_stack((train_input ** 2, train_input))
test_poly = np.column_stack((test_input ** 2, test_input))
#다항회귀
lr=LinearRegression();
lr.fit(train_poly,train_target);1차 함수에서는 기울기와 절편에 대한 이해가 잘 되었다.
하지만 2차 함수에서는 기울기와 절편에 따라 식이 어떻게 바뀔까?
print(lr.coef_, lr.intercept_)실제로 확인해보면 다음과같이 나온다.
[ 0.99791475 -22.04619219] 135.29317111947813
그럼 식은 <<무게 = 0.99 * 길이*길이 - 22*길이 +135.29>>
#산점도
point = np.arange(15, 50)
plt.plot(point, 1.01*point**2 - 21.6*point + 116.05)
plt.scatter(train_input, train_target)
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
#테스트
print(lr.score(train_poly,train_target))
print(lr.score(test_poly,test_target))산점도와 결정 계수도 살펴보자

실제 구한 2차함수과 산점도 그림과 매우 유사함을 알 수 있다.
또, 훈련세트의 결정계수와 테스트세트의 결정계수가 둘다 높아졌고 비슷해진 것을 알 수 있다.
k근접은 범위 밖에 있다면 아무리 멀리 떨어져도 무조건 가장 가까운 샘플로 측정하기 때문에
범위 밖의 값으로 예측을 요구한다면 만족스럽지 못한 결과가 나왔다.
하지만 선형 회귀로는 직선으로 쭈욱 예측한 값의 그래프를 그려주기 때문에 범위밖에 값도 예측할 수 있다.
'공부 > 머신러닝' 카테고리의 다른 글
| [ 머신러닝 프로그램 ] k최근접 이웃 회귀 알고리즘 (0) | 2023.02.13 |
|---|---|
| [ 머신러닝 프로그램 ] k-최근접 이웃 분류 알고리즘 ver3 - 데이터 전처리 (0) | 2023.02.13 |
| [ 머신러닝 프로그램 ] k-최근접 이웃 분류 알고리즘 ver2 - 테스트 세트 추가 (0) | 2023.02.11 |
| [ 머신러닝 프로그램 ] k-최근접 이웃 분류 알고리즘 ver1 (0) | 2023.02.10 |