DataFrame객체.loc[행인덱스, 열이름]
DataFrame객체.iloc[행번호, 열번호]데이터는 형태나 속성이 매우 다양하다.
서로 다른 형식을 갖고 있는 데이터들을 컴퓨터가 이해할 수 있도록 하기 위해서는 구조를 통합해줘야한다.
이를 위해 판다스는 1차원 배열인 시리즈와 2차원 배열인 데이터 프레임이라는 구조화된 데이터 형식을 제공한다
판다스의 1차적인 목적은 서로 다른 데이터 형식을 공통의 포멧으로 만드는 것이다.
1. 시리즈
시리즈는 데이터가 순차적으로 나열된 1차원 배열의 형태를 갖는다.
인덱스와 데이터 값은 일대일 대응이된다.
파이썬의 딕셔너리와 비슷하다고 볼 수 있다.
1.1. 딕셔너리를 시리즈로 변환
pandas.Series(딕셔너리) #딕셔너리->파이썬1.2 인덱스와 배열
series객체.index #인덱스 배열
series객체.values #데이터 값 배열아래와 같이 인덱스를 따로 지정해주지 않으면 디폴트로 0,1,2... 정수형 인덱스가 들어가게된다.
import pandas as pd
list_data=['2022','3','AA','10000','True']
sr=pd.Series(list_data)
print(sr)
"""
0 2022
1 3
2 AA
3 10000
4 True
dtype: object
"""1.3 원소 선택
인덱스를 이용하여 시리즈의 원소를 선택할 수 있다.
하나의 원소를 선택할 수도 있고, 여러개를 선택할 수도 있다.
정수형 위치 인덱스로 슬라이싱 할 때는 [a:b] a부터 b를 포함하지 않고 선택이되고
인덱스 이름으로 슬라이싱할 때는 a:b] a부터 b를 포함하고 선택된다.
import pandas as pd
# 투플을 시리즈로 변환(index 옵션에 인덱스 이름을 지정)
tup_data = ('영인', '2010-05-01', '여', True)
sr = pd.Series(tup_data, index=['이름', '생년월일', '성별', '학생여부'])
print(sr)
print('\n')
# 원소를 1개 선택
print(sr[0]) # sr의 1 번째 원소를 선택 (정수형 위치 인덱스를 활용)
print(sr['이름']) # '이름' 라벨을 가진 원소를 선택 (인덱스 이름을 활용)
print('\n')
# 여러 개의 원소를 선택 (인덱스 리스트 활용)
print(sr[[1, 2]])
print('\n')
print(sr[['생년월일', '성별']])
print('\n')
# 여러 개의 원소를 선택 (인덱스 범위 지정)
print(sr[1 : 2]) #생년월일만 출력
print('\n')
print(sr['생년월일' : '성별']) #생년월일, 성별 출력
2. 데이터 프레임
데이터프레임은 2차원 배열이다.
열은 각각 시리즈 객체이다. 행은 index라고 볼 수 있다.
따라서 행은 행인덱스라고 부르고 열은 열 이름이라고 부른다.
행은 이름, 가격 과 같은 공통속성을 나타내고 행은 관측값을 나타낸다,
2.1 데이터프레임 만들기
데이터 프레임을 만들기 위해서는 1차원 배열 여러개가 필요하다.
데이터 프레임은 여러개의 시리즈를 열로 모아놓은 집합으로 이해하면 된다.
딕셔너리의 값에는 열에 해당하는 리스트를 저장하고 키에는 시리즈의 이름, 즉 열의 이름이 저장된다.
행인덱스는 자동을 0,1,2,3,,등이 배정된다.
pandas.DataFrame{딕셔너리객체} //딕셔너리->데이터프레임
import pandas as pd
# 열이름을 key로 하고, 리스트를 value로 갖는 딕셔너리 정의(2차원 배열)
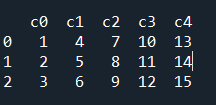
dict_data = {'c0':[1,2,3], 'c1':[4,5,6], 'c2':[7,8,9], 'c3':[10,11,12], 'c4':[13,14,15]}
# 판다스 DataFrame() 함수로 딕셔너리를 데이터프레임으로 변환. 변수 df에 저장.
df = pd.DataFrame(dict_data)
# df의 자료형 출력
print(type(df))
print('\n')
# 변수 df에 저장되어 있는 데이터프레임 객체를 출력
print(df)위의 예제를 실행시키면 아래와같은 결과가 나오게된다.
2.2 행 인덱스/열 이름 설정 및 변경
행인덱스와 열 이름은 직접설정할 수도 있고, 새로운 이름을 지정해줄 수 있고, 일부만 변경해줄 수도 있다 .
아래 코드는 그에 대한 예시이다.
# 행인덱스, 열인덱스 이름 설정
pandas.DataFrame(2차원 배열, index이름배열, columns이름배열)
DataFrame객체.index = 새로운이름 #행인덱스 이름변경
DataFrame객체.columns = 새로운이름 #열 이름변경
#행인덱스 일부 수정, rename은 새로운 객체반환, inplace=True 를 추가해주면 원본객체에서 변경
DataFrame객체.rename(index={기존인덱스,새인덱스},inplace=True)
DataFrame객체.rename(columns={기존인덱스,새인덱스},inplace=True)위에서 배운 코드를 예제를 통해 실습해보면 아래와 같다.
#예제
# -*- coding: utf-8 -*-
"""
Spyder Editor
This is a temporary script file.
"""
import pandas as pd
#데이터프레임만들기
df=pd.DataFrame([[15,"남", "덕양중"],[17, "여", "수리중"]],index=["준서","예은"],columns=["나이","성별","학교"])
print(df)
#데이터프레임 행렬이름변경
df.index=["학생1","학생2"]
df.columns=["연령","남녀","소속"]
print("\n")
print(df)
#데이터프레임 행렬 일부변경
df.rename(index={"학생1":"준서"},inplace=True)
df.rename(columns={"남녀":"성별"},inplace=True)
print("\n")
print(df)
2.3 행/열 삭제
데이터 프레임의 행 도는 열을 삭제하는 명령으로는 drop() 메소드가 있다.
이에는 axis라는 옵션이 있는데 이 값이 0이면 행을 삭제하는 것이고 1이면 열을 삭제하는것이다.
(axis의 기본값은 0이다.)
삭제할 행/열은 이름이나 배열로 표현하면되고 여러개를 삭제하고 싶다면 리스트로 입력하면된다.
drop() 또한 새로운 객체를 반환하는 메소드이기 때문에 변경하고 싶다면 inplace=True를 추가해줘야한다.
DataFrame객체.drop(행 이름 또는 배열, axis=0)
DataFrame객체.drop(열 이름 또는 배열, axis=1)import pandas as pa
df=pa.DataFrame([[90,98,85,100],[80,89,95,90],[70,95,100,90]],index=["서준","우현","인아"]
,columns=["수학", "영어","음악","체육"])
df2=df[:] #데이터프레임 복제
print(df)
print("\n")
#2행 삭제
df.drop("우현",inplace=True,axis=0)
print(df)
print("\n")
#2,3행 삭제
df2.drop(['우현',"인아"],inplace=True,axis=0)
print(df2)
print("\n")
# 2,3행 삭제
df.drop(["영어","음악"],inplace=True,axis=1)
print(df)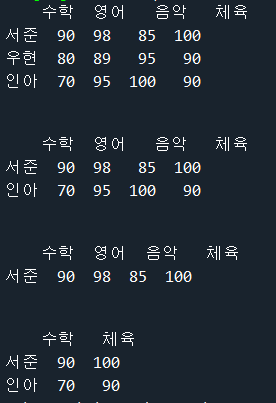
2.4 행 선택
데이터 프레임의 행 데이터를 선택하기 위해서는 loc와 iloc 인덱서를 사용한다.
인덱스 이름을 기준으로 행을 선택할 때는 loc를 이용하고, 정수형 위치 인덱스를 사용할 때는 ilco를 이용한다.
둘다 슬라이스로 범위지정이 가능하지만 이른으로 범위를 지정해 줄 때는 마지막 인덱스가 포함된다는 것을 기억해야한다
import pandas as pd
# DataFrame() 함수로 데이터프레임 변환. 변수 df에 저장
exam_data = {'수학' : [ 90, 80, 70], '영어' : [ 98, 89, 95],
'음악' : [ 85, 95, 100], '체육' : [ 100, 90, 90]}
df = pd.DataFrame(exam_data, index=['서준', '우현', '인아'])
print(df) # 데이터프레임 출력
print('\n')
# 행 인덱스를 사용하여 행 1개를 선택
label1 = df.loc['서준'] # loc 인덱서 활용
position1 = df.iloc[0] # iloc 인덱서 활용
print(label1)
print('\n')
print(position1)
print('\n')
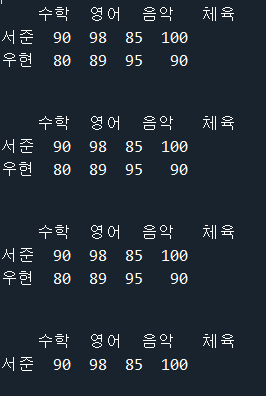
# 행 인덱스를 사용하여 2개 이상의 행 선택
label2 = df.loc[['서준', '우현']]
position2 = df.iloc[[0, 1]]
print(label2)
print('\n')
print(position2)
print('\n')
# 행 인덱스의 범위를 지정하여 행 선택
label3 = df.loc['서준':'우현']
position3 = df.iloc[0:1]
print(label3)
print('\n')
print(position3)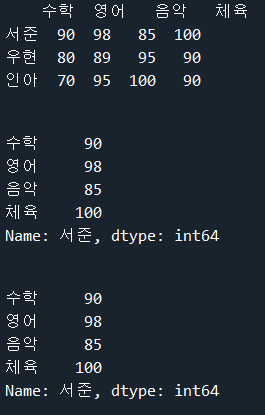
2.5 열 선택
데이터 프레임의 열 데이터를 한개 선택할 때는 대괄호 안에 열 이름을 따옴표와 함께 입력하거나 도트 다음에 열 이름을 입력하는 두가지 방법을 사용한다. 여러개를 하고싶을 때는 대괄호 안에 리스트를 넣으면 된다.
DataFrame객체["열이름"]
DataFrame객체.열이름
DataFrame[[열리스트]]
*슬라이싱 활용
객체iloc.[시작인덱스:끝인덱스:간격]
2.6 원소선택
데이터프레임의 행 인덱스와 열 이름을 [행,열] 형식의 2차원 좌표로 입력하려 원소위치를 지정할 수 있다.
원소 하나를 지정하면 원소로 반환되고 원소 두개 이상의 시리즈 모양을 지정하면 시리즈로 반환된다.
행과 열 다 여러개씩 지정한다면 데이터 프레임으로 반환된다.
DataFrame객체.loc[행인덱스, 열이름]
DataFrame객체.iloc[행번호, 열번호]
import pandas as pd
# DataFrame() 함수로 데이터프레임 변환. 변수 df에 저장
exam_data = {'이름' : [ '서준', '우현', '인아'],
'수학' : [ 90, 80, 70],
'영어' : [ 98, 89, 95],
'음악' : [ 85, 95, 100],
'체육' : [ 100, 90, 90]}
df = pd.DataFrame(exam_data)
# '이름' 열을 새로운 인덱스로 지정하고, df 객체에 변경사항 반영
df.set_index('이름', inplace=True)
print(df)
print('\n')
# 데이터프레임 df의 특정 원소 1개 선택 ('서준'의 '음악' 점수)
a = df.loc['서준', '음악']
print(a)
b = df.iloc[0, 2]
print(b)
print('\n')
# 데이터프레임 df의 특정 원소 2개 이상 선택 ('서준'의 '음악', '체육' 점수)
c = df.loc['서준', ['음악', '체육']]
print(c)
d = df.iloc[0, [2, 3]]
print(d)
e = df.loc['서준', '음악':'체육']
print(e)
f = df.iloc[0, 2:]
print(f)
print('\n')
# df의 2개 이상의 행과 열로부터 원소 선택 ('서준', '우현'의 '음악', '체육' 점수)
g = df.loc[['서준', '우현'], ['음악', '체육']]
print(g)
h = df.iloc[[0, 1], [2, 3]]
print(h)
i = df.loc['서준':'우현', '음악':'체육']
print(i)
j = df.iloc[0:2, 2:]
print(j)2.7 열추가
아래의 방법으로 열을 추가하면 데이터프레임의 마지막에 열을 덧붗이듯 새로운 열을 추가한다.
DataFrame객체['추가하려는 열 이름'] = 데이터값
이때의 모든 칸에 모두 같은 데이터 값이 들어가데된다.
2.8 행추가
행추가에는 loc를 이용한다.
이는 하나의 데이터값을 입력하거나, 열의 개수에 맞게 배열 형태로 여러개의 값을 입력할 수 있다.
전자의 경우에는 모든 원소에 같은 값이 추가된다.
후자의 경우 배열의 순서대로 열 위치에 값이 하나씩 추가된다.
DataFrame.loc["새로운 행 이름"] = 데이터 값 또는 배열새로운 행 이름이 원래의 인덱스와 이름이 같다면 원래의 행이 수정된다.
행의 이름이 규칙에 따르지 않아도된다.
2.9 원소 값 변경
데이터프레임의 특정원소를 선택하고 새로운 데이터 값을 지정해주면 원소 값이 변경된다.
DataFrame객체의 일부분 선택 = 새로운값#여러개를 한번에 바꾸는 것
df.loc['서준', ['음악', '체육']] = 50
print(df)
print('\n')
df.loc['서준', ['음악', '체육']] = 100, 50
print(df)
2.10 행, 열의 위치 바꾸기
데이터프레임의 행과 열을 서로 맞바꾸는 것디아.
선대의 전치행렬과 같은 개념이다.
전치의 결과로 새로운 객체를 반환하므로 , 기존 객체를 변경해주기 위해서는 기존객체에 새로운 객체를 할당해줘야한다.
DataFrame객체.transpose()
DataFrame객체.T
'공부 > 판다스 데이터분석' 카테고리의 다른 글
| [ Pandas ] 웹, API를 활용하여 데이터 수집하기 (0) | 2023.01.28 |
|---|---|
| [ Pandas ] 외부 파일 읽어오기(CSV, EXCEL, JSON) (0) | 2023.01.19 |
| [ Pandas ] 산술연산 (시리즈, 데이터프레임) (0) | 2023.01.10 |
| [ Pandas ] 인덱스 활용 (0) | 2023.01.07 |