1. Transaction Concept
transaction이란 data에 접근하고 업데이트할 수 있는 프로그램의 실행 단위이다.
DBS는 사용자가 트랜잭션의 기능을 잘 사용하기 위해 2가지 상황을 잘 처리해야한다.
- 하드웨어 오류 및 시스템 충돌(seg fault)과 같은 오류
- 여러 transaction들이 동시 실행 → 성능
위의 두가지 상황이 일어나도 트랜젝션은 intergrity를 보존하기 위해 ACID를 보장해야한다.
ACID
Atomic requitement
트랜잭션은 전체가 DB에 반영되거나 아무것도 반영되지 않거나 하는 원자적인 상태여야한다. 일부만 실행되고 종료되어도 DB에 업데이트하면 안된다.
Consistency requirement
트랜잭션이 시작하기 전과 끝난 후의 DB의 상태는 일관되어야한다. 트랜잭션이 독립적으로 Atomic하게 실행된다면 이는 유지된다.
Isolation requirement
트랜잭션끼리는 동시에 여러개가 실행되어도 서로 영향을 주지 않고 독립적으로 실행되어야한다. 중간 트랜잭션의 결관느 다른 트랜잭션이 알지 못하게 해야한다.
Durability requirement
사용자에게 트랜잭션이 끝난다는 것을 통지했다면, SW나 HW에 장애가 생기더라도 트랜잭션에 대한 업데이트는 유지되어야한다.
2. Transaction Atomicity and Durability
2.1 Transaction state

- Active
- 초기상태. 트랜잭션이 실행되는 동안 이 상태를 유지한다
- Partially committed
- 최종 statement가 실행 된 후의 상태
- Failed
- 에러를 발견해서 실행할 수 없는 상태
- Aborted
- 트랜젝션이 rollback되고 DB가 시작 전 상태로 복원된 상태
- 이 상태에서는 트랜잭션을 종료하거나 다시 실행한다.
- Commited
- 트랜잭션을 성공적으로 commit한 상태
2.2 Concurrent Execution
시스템에서 여러개의 트랜잭션이 동시에 실행하면 다음과같은 장점이 있다.
- processor와 disk의 활용도가 높아져 처리속도가 증가한다 한 트랜젝션이 cpu를 사용하는동안 다른 트랜덱션은 I/O를 할 수 있음.
- transaction에 대한 평균 응답 속도가 짧아진다. 짧은 트랜잭션이 킨 트랜잭션 뒤에서 기다릴 필요 없음.
이렇게 동시에 트랜잭션들이 실행되면 데이터들의 consistency가 무너지지 않도록 Concurrency control Scheme를 사용함. Chapter18에서 더 자세히다룬다.
2.3 Schedules
여러 트랜잭션이 동시에 실행되도 isolation을 보존하기 위해서는 트랜잭션들을 적절하게 schedualing해줘야한다. schedule은 동시에 수행되고 있는 트랜잭션의 명령어 순서를 지정해준다. 이때, 특정 트랜잭션들의 스케줄은 트랜잭션들의 모든 명령어를 다 포함되어야하고, 개별 트랜잭션들의 명령어 순서를 보존해줘야한다. 성공적으로 실행이 끝난 트랜잭션은 commit명령어를 가져야하고, 실행에 실패한 트랜잭션은 abort 명령어를 가져야한다.
Sirial Schedule


위 그림과 같은 트랜잭션 두개가 있다고 해보자. 이렇게 순서와 상관없이 순차적으로 하나 끝내고 하나를 실행시키는 것을 sirial schedule이라고 한다. 이는 결과는 달라질 수 있지만 두 트랜잭션의 isolation은 보장된다
Serializable Schedule


serial하게 실행되지 않아도 serial하게 실행된 것 과 결과가 같다면 이를 serializable 하다고 한다. 위 두 결과는 같은 결과를 낸다. 왼쪽은 한 트랜잭션이 끝나기 전에 다른 트랜잭션이 실행 되었지만 T1의 A연산을 마지고 T2의 A연산을 마치고 그 뒤 B연산을 수행하였기 때문에 결과는 동일하다.

이 스케줄은 serial하지도 않고 serializable하지도 않다. 이들은 서로 영향을 주고 있고 각 트랜잭션들의 isolation이 지켜지지 않고 있다. read 연산만 있을 때는 크게 서로 영향을 끼치지 않지만 write연산이 들어가게되면 실행순서가 중요하게 된다.
2.4 Serializability
serializable한 스케줄을 serializability라고 한다. 우리는 이 스케줄 serializability인지 아닌지 판단하는 방법을 알아볼 것이다. 트랜잭션의 isolation을 방해하는 경우는 read와 write를 할 때이다. 따라서 우리는 serializability를 판단할때 cache를 읽고 쓰는 동작만 고려할 것이다. 트랜잭션 두개가 conflict 한다는건 둘 중에 하나 이상의 명령어가 둘이서 공유하고 있는 데이터를 write했다는 것이다. 이에 write가 있다면 순서를 강제해야한다.
serializability은 엄격한 Conflict serializability 와 완화된 View serializability가 있다.
Conflict serializability
S라는 스케줄 안에 non-conflicting한 명령어 몇개를 swap 하여 S’를 만들었다고 해보자. 이때 S’가 여전히 non-conflicting 상태라면 우리는 S와 S’가 confilct equivalent하다고 한다.
만약 스케줄 S가 serial schedule와 conflict equivalent라면 스케줄 S는 conflict serializable하다고 한다.



두번째 사진은 conflict serializability의 한 예시이다.
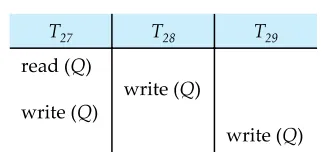
하지만 세번째 사진은 T3이 실행되는 도중에 Q의 값이 T4에 의해 변하게 되었기 때문에 confrict가 일어난다. 따라서 이는 conflict serializability가 아니다.
View serializability
view serializability는 read와 write 기반의 규칙 3가지를 성립하면 성립한다.
- S에서 T1가 Q의 초기값을 read 했다면 S’도 T1이 Q의 초기값을 read해야한다.
- S에서 T1가 T2가 쓴 Q를 읽었다면 S’에서도 똑같이 T2가 쓴 Q를 T1가 읽어야한다.
- S에서 마지막으로 Q를 쓴 트랜잭션이 S’에서도 마지막 값을 써줘야한다.
위 예시는 write이 순서가 바껴 conflict serializability하지는 않다. 하지만 잘 보면 위의 3가지 조건을 다 만족하여 view serializability는 만족한다.
non conflict serializable한 모든 view serialzable 스케줄은 blind write를 가진다. blind write란 트랜잭션에서 데이터를 쓰는 작업을 할 때 해당 데이터의 상태와 상관없이 데이터를 쓰는 동작이다.

이 스케쥴은 <T1, T5>와 동일한 결과를 낸다.
하지만 view serializable하지도 않고 conflict serializable 하지도 않다. B의 초기값은 원래 T1이 읽었어야했는데 T5가 먼저 읽었기 때문이다. T2가 T1의 트랜잭션이 끝나기전에 B를 건드려 T1의 isolation을 침범했다.
Testing for conflct serializability
Precedence graph란 트랜잭션의 이름을 노드로 하는 direct 그래프를 의미로한다. 두 트랜잭션이 충돌하면 먼저 데이터에 액세스한 트랜잭션으로부터 다른 트랜잭션으로 화살표를 그린다.
어떤 스케줄의 Precedence graph가 비순환이라면 그 스케줄은 coflict serializable이다. Precedence 그래프가 비순환인 경우 topological 정렬 알고리즘을 통해 순서를 얻을 수 있다.


이때 Ti와 Tk의 순서는 어떻게 해도 상관 없다.
Test for View Serializability
view serializable는 판별하기 쉽지 않다. 차라리 조건을 하나하나 체크하는 것이 거 실용적이다.
Conflict equivalent & Conflict serializability
conflict serializability는 더 엄격하지만 우리가 원하는 결과게 더 가깝기 때문에 실제로 BDMS에서 더 많이 사용된다. 하지만 실제로 conflict serializability는 consistency 문제를 가지지 않은 serializable 스케줄의 부분집합만 허용한다. 일반적인 형태의 view serializability는 테스트하기에 너무 많은 비용이 든다.
3. Transaction Isolation and Atomicity
3.1 Recoverable Schedules
우리는 지금까지 트랜잭션의 실패가 없다고 가정하고 스케줄을 공부하였다. 이번에는 동시 실행중인 트랜잭션이 실패했을 때를 알아보자. 트랜잭션은 원자성을 보장해야하기 떄문에 트랜잭션이 실패했다면 그 전으로 상태를 돌려야한다. 이때 실패한 트랜잭션이 썼던 데이터를 읽은 다른 트랜잭션도 중단되어야한다. 이를 위해 사용할 수 있는 스캐줄의 유형을 알아보자.
recoverable schedule에서는 랜잭션 T1이 T2가 write한 item을 읽는다면 T2에서의 commit operation이 T1에서의 commit operation보다 먼저 실행되어야한다

위 그림은 recoverable하지 않다. 만약 T9가 이미 commit된 후에 T8의 트랜잭션이 실패하게 되면 T8이 적었던 내용은 rollback 되어 없어지겠지만 T9는 이를 알지 못래 data inconsistency가 발생하게 될 것이다.
3.2 Cascade Rollbacks
이는 하나의 트랜잭션이 실패하면 연속적으로 다른 트랜잭션도 rollback 해주는 것이다.

위 상황으로 봤을 때 T10이 abort 되었기 때문에 T10이 적은 A를 읽은 T11과 T12도 rollback해줘야한다. 이러한 동작은 상당한 양의 rollback을 불러올 수 있으며 이는 성능을 떨어트린다.
3.3 Cascadeless Schedules
이는 cascading rollback이 없이 recoverable한 스케줄이다. 이는 T1이 T2가 write(Q)한 Q를 읽는다면 T2의 commit operation이 T1의 read operation보다 먼저 나오게 한다 이렇게 되면 모든 transaction은 commit된 데이터만을 읽을 수 있다. 이는 isolation을 보장한다. cascade rollback은 너무 비용이 크기 때문에 제한하는것이 바람직하다.
4. Concurrency Control
DBMS는 conflict serializable하거나 view serializable하고, recoverable하며 가급적이면 cascadeless이도록 스케줄을 결정한다. 그리고 가급적 많은 트랙잭션이 동시에 진행되 수 있도록 한다.
concurrenct control은 트랜잭션의 동시성과 그에 따른 오버헤드의 양을 trade-off한다.
4.1 Weak Levels of Consistency
일부 응용 프로그램은 약한 수준의 일관성을 유지하여 serialzable하지 않은 스케줄을 허용한다. 이는 동시성을 포기하고 성능을 얻은 케이스라고 볼 수 있다.
On Line Transaction Processing –OLTP
실시간 트랜잭션 처리를 위해 설계된 DBS이다. 이는 보통 업무 응용프로그램에 많이 사용되며, 많은 양의 작은 트랜잭션을 처리하는 데 중점을 둔다. OLTP 시스템은 데이터의 신속한 읽기 및 쓰기 작업, 동시 다중 사용자 지원, 데이터 일관성, 원자성 및 데이터 무결성을 보장하는 것이 중요하다. 주로 은행, 예약 시스템, 주문 처리 등의 온라인 업무 처리에 사용된다.
On Line Analytic Processing –OLAP
대규모 데이터 분석과 의사 결정 지원을 위해 설계된 데이터베이스 시스템이다. 이는 주로 복잡한 질의와 다차원 분석을 수행하는 데 중점을 둔다. 이는 데이터가 항상 최신일 필요가 없기 때문에 OLTP에 비해 동시성 수준은 낮다.
4.2 Phenomena caused by Concurrent Transactions
이는 동시성을 잘 관리하지 않았을 때 발생되는 문제들이다.
dirty read
commit하지 않은 트랜잭션이 쓴 data를 읽은 경우
nonrepeateatable read
한 트랜잭션 안에서 같은 쿼리를 두번 실행하여 data를 두번 읽었는데 다른 트랜잭션에 의해 수정된 경우
phantom read
한 트랜잭션 안에서 같은 쿼리를 두번 실행하여 data를 두번 읽었는데 다른 트랜잭션에 의해 새로운 값이 추가된 경우
serialization anomaly
모든 트랜잭션이 모두 성공했는데 serial하게 실행한 것과 결과가 다른경우.
'학부 내용 정리 > [ 3-1 ] 데이터베이스' 카테고리의 다른 글
| [ DB ] Chapter 19. Recovery System (0) | 2025.09.04 |
|---|---|
| [ DB ] Chapter 18. Concurrency Control (0) | 2025.09.04 |
| [ DB ] Chapter 14. Indexing (0) | 2025.09.02 |
| [ DB ] Chapter 13. Data Storage Structures (0) | 2025.09.02 |
| [ DB ] Chapter 12. Physical Storage Systems (1) | 2025.09.02 |