해당 게시물은 건국대학교 김욱희 교수님의 데이터베이스 강의와
DATABASE SYSTEM CONCEPTS 7th 원서를 참고하여 작성하였습니다.
1. Structure of Relational DB
ralational database는 unique 한 이름을 가진 table의 모음으로 이루어져있다.

이는 instruct라는 relation이다. 나와있는대로 각 행을 attributes혹은 columns라고 부르고 각 열을 tuples혹은 rows라고 부른다.
relation의 domain이란 attribute와 대응하는 열에 대한 데이터 타입(Data Type)과 길이를 의미한다. 이는 atomic 해야한다. 즉, 값을 둘로 나누거나 할 수 없다는 의미이다. 모든 도메인은 null값을 포함 하고 있다.
2. DB Schema
relation schema
A_1, A_2,..., A_n이 attributes라고 한다면, 이를 포함하는 relation R은 R=(A_1, A_2,..., A_n)으로 표현된다.
relation의 instance r은 r(R)로 표현된다.
relation들은 보통 정렬되지 않은 상태이다.
DB schema
database란 여러개의 relation들로 이루어져있다. 한 relation에 너무 많은 정보를 담는것은 유지차원에서 좋지 않다. 이는 중복을 야기할 수도 있고 null값이 매우 많아 질 수도 있기 때문이다.
3. Key
어진 relation 내에서 튜플들이 구별되기 위해서는 튜플의 속성 값들은 고유하게 식별할 수 있어야한다. 또, 완벽이 똑같은 튜플을 두개 이상 가지고 있을 수 없다.
Super key
relation안에서 튜플을 unique하게 해주는 attribute값의 집합을 superkey라고 한다. superkey는 확장할 수 있다. {ID}와 {ID, name} 모두 superkey가 될 수 있다.
Candidate Key
superkey들 중에 제일 크기가 작은 superkey를 candidate key라고 한다. {ID}와 {ID, name} 모두 superkey라면 {ID}가 candidate key이다.
primary key
candidate key들 중에서 필요에 의해 고른 한 candidate key 를 primary key라고 한다.
foreign key
다른 ralation의 attribute값을 참조하고 있는 attribute을 foreign key라고 한다.
4. Schema Diagram
Schema Diagram은 superkey, candidate key, foreign key 의 정보를 모두 포함하고 있는 DB schema이다.
사각형 하나가 하나의 relation이고 파란칸은 relation의 이름이다.
primary key 는 밑줄로 명시되어있다.
foreign key 는 화살표로 표현되어있고 화살표가 출발하는 쪽이 foreign key, 화살표가 도착하는 곳이 primary key여야 한다.
5. Relaltional Algebra
쿼리 언어는 사용자가 데이터베이스에게 정보를 요청하는 언어이다. 이러한 언어는 일반적으로 프로그래밍 언어보다는 높은 수준을 갖는다.
그 중에서도 relational Algebra는 SQL과 같이 구조화된 쿼리와 같은 표현력을 가진 순수언어이다. 이는 중복을 자동으로 제거한다.
Relaltional Algebra는 6개의 기본적인 연산자로 동작한다. 연산의 결과는 relation으로 반환된다.
select operation
select operation은 조건에 만족하는 튜플들을 반환한다. 조건문에는 부등호, 등호, and or not을 모두 사용할 수 있다.
project operation
relation에서 아래첨자에 해당하는 property만으로 구성된 relation을 반환한다. 만약 새로운 relation을 구성할때 중복되는 row가 생기면 중복을 제거한 채로 relation을 만들어 반환한다.
set operation
각각 합집합, 교집합, 차집합을 수행한다. union 이 가능하려면 두 relation의 attribute 수와 해당 속성의 domain이 동일해야 한다. union연산은 자동으로 중복되는 tuple을 제거해 준다.
join operation
Cartesian Product(x)는 곱하기와 같은 기능을 수행한다. 모든 경우의 수를 가진 relation을 출력한다. 10개의 행을 가진 relation두개가 곱해지만 100개의 행이 만들어지게 된다.
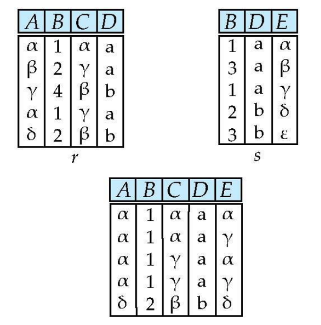
Natural Join은 두 테이블에서 이름이 같은 column간의 equal조건으로 join을 수행한다. r과 s를 join 하되 중복되는 이름의 column을 제거한다. 즉 결과물에서는 A column이 하나만 존재한다
rename operation
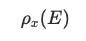
E라는 relation에 x라는 이름을 붙여준다.

E라는 relation에 x라는 이름을 붙여주고, attribute를 A1, A2,..An으로 붙여준다.
'학부 내용 정리 > [ 3-1 ] 데이터베이스' 카테고리의 다른 글
| [ DB ] Chapter 4. Intermediate to SQL (0) | 2025.04.02 |
|---|---|
| [ DB ] Chapter 3. Introduction to SQL (0) | 2025.03.28 |
| [ DB ] Chapter 1. Introduction to DB (0) | 2024.03.08 |