해당 게시물은 건국대학교 김욱희 교수님의 데이터베이스 강의와
DATABASE SYSTEM CONCEPTS 7th 원서를 참고하여 작성하였습니다.
1. Join Expressions
join은 두개의 relation을 합쳐 하나의 relation을 만들어 주는 연산자이다. 이는 from에 서브쿼리로도 많이 쓰인다.
Natural Join
natural join은 relational algebra에서 나온 의미와 동일하다. 같은 attribute의 튜플 값이 같은 attribute끼리만 곱셈연산을 취한다. 아래의 두 쿼리는 같은 결과를 도출한다.


이는 두 테이블 외에도 여러 테이블에 적용할 수 있다. 하지만 이는 오답률이 높다. 두개의 테이블이 이름은 같고 의미는 다른 attribute를 가지고 있다면 충돌이 될것이다. 그렇기 때문에 natural join을 여러개 쓰는것보다 where문으로 표현해주는 것이 더 좋다.
natural join은 using구문으로 사용할 attribute를 명시하기도 한다.
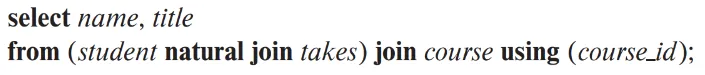
이것을 사용하면 같은 이름의 열이 여러개 있어도 명시된 열을 기준으로 수행된다. 따라서 이를 이용하면 여러개를 natural join할 때 충돌없이 할 수 있다.
Inner Join

inner join은 on과 함께 사용해야한다. natural join은 이름이 같은 열을 자동으로 찾아주지만 inner join은 on 혹은using으로 열을 지정해줘야한다.
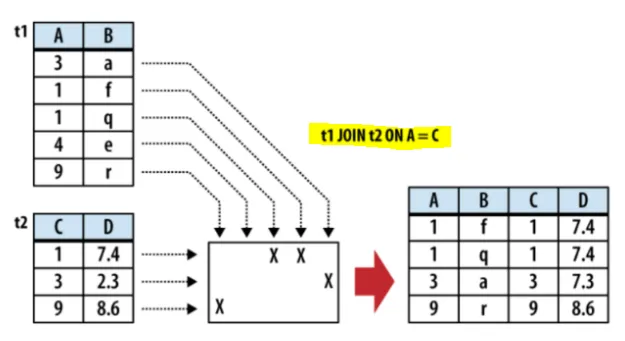
on뒤에는 join할 조건을 명시해주면 되고 using뒤에는 이용할 열을 지정해주면 된다. 그후 같은 튜플을 찾아 join을 수행하고 같은 튜플이 없을 경우 버려진다.
inner join은 inner를 생략하고 쓰기도한다. 하지만 그냥 join이라고 명시하고 on이나 using으로 조건을 걸어주지 않으면 카르시안 곱을 수행하게 된다.
Outer join
outer join은 inner join에서 같은 튜플이 없어 버려지는 데이터들을 null을 이용하여 포현한다. 이는 on과 using을 사용하여 조건을 나타내 주거나 natural를 추가해줘야한다. outer join은 다음과같은 3종류가 존재한다.
- Left Outer Join : 쿼리문을 기준으로 왼쪽에 위치한 table을 기준으로 오른쪽의 위치한 table과 조건에 따른 join을 수행한다. 이때 조건에 맞지 않은 왼쪽 table의 정보도 제공된다.
- Right Outer Join : 쿼리문을 기준으로 오른쪽에 위치한 table을 기준으로 왼쪽의 위치한 table과 조건에 따른 join을 수행한다. 이때 조건에 맞지 않은 오른쪽 table의 정보도 제공된다.
- Full Outer Join : 조건에 따른 join을 수행하고 조건에 맞지 않은 튜플들의 정보도 제공된다.
이들은 relational algebra로 각각 다음과같이 표현된다.


모든 join type은 모든 join conditiond과 결합하여 사용할 수 있다.
2. Views
전에 with문을 배우며 잠깐 언급했던 view에 대한 내용을 공부하는 부분이다. view는 미리 계산되어서 저장되는 것이아니라 사용될 때마다 쿼리를 실행하여 계산된다.
View Definition
view는 creat view~ as~를 통하여 정의된다. view뒤에는 view의 이름과 attribute를 명시해줄 수 있고 as뒤에는 select문으로 view에 저장될 값들을 정의해줘야한다.
Using Views in SQL Queries
v1을 이용하여 v2를 만든경우 v2는v2에 직접 의존한다고 한다. 혹은 경로중에 종속경로가 있는 경우에도 종속한다고 한다.
자기 자신에 의존하는 경우도 있지만 잘 사용하지 않는다.

아래 쿼리문에서는 위 커리문에서 만들어진 view를 활용하여 새로운 view를 만들었다. 그렇기 때문에 physics_fall_2017_watson은 physics_fall_2017의존한다고 말할 수 있다.
뷰의 내용은 테이블이 업데이트 될때마다 업데이트 되어야하므로 뷰의 의존관계를 잘 이용하면 유연하게 잘 업데이트할 수 있다.
Materialized Views
일부 DBMS에서는 뷰 관계를 저장할 수 있도록한다. 이때, 뷰 정의에 사용된 실제 테이블이 변경된 경우 뷰가 최신상태를 유지하도록 보장한다. 이러한 뷰를 Materialized view라고 한다.
일반적은 view는 자동으로 업데이트되지 않으므로 materialized view는 따로 지정해줘야한다.
Update of a View
view를 업데이트하기 위해서는 view를 만들때 사용했던 relation을 이용해야한다. view를 직접 수정하게되면 relation이 수정되게되고 제약조건을 어기게 될수도있다. 그렇기 때문에 view를 수정해야하는 경우에는 보통 기본 relation을 수정하고 view가 업데이트 되도록한다.

만들어진 view는 사학과 교수님들의 정보를 모아놓은 view인데, 아래와 같은 data를 insert하면 의도와 맞지 않을 것이다.
이러한 이유로 view는 update가 많을때는 보통 사용하지 않고 select,즉 read가 주 목적일때 사용한다.
대부분의 SQL은 simple한 view에게만 업데이트를 허용한다. view의 조건은 다음과같다.
- from절에 하나의 relation만 존재해야한다.
- select절에는 relation의 attribute이름만 포함되어야하고 expressions, aggregates, 또는 distinct specification가 없어야한다.
- select절에 나열되지 않은 attribute를 null로 설정할 수 있어야한다.
- 쿼리에 group by나 having 절이 없어야한다.
3. Transactions
transaction은 하나 이상의 쿼리나 업데이트 문장으로 이루어진 작업 단위이다. 이는 한번에 모두 실행되도록한다. 하나의 transaction은 다음 중 하나의 SQL 문장으로 트랜잭션을 끝낸다
- Commit work : 현재 수행한 트랜잭션을 커밋한다. 커밋이 되면 트랜잭션에서 수행한 업데이트는 데이터베이스에 영구적으로 저장되고 커밋이 완료되면 새로운 트랜잭션이 자동으로 시작된다.
- Rollback work : 현재 트랜잭션을 롤백한다. 롤백이 되면 트랜잭션에서 수행한 모든 업데이트를 취소하고, 데이터베이스 상태를 트랜잭션 이전 상태로 되돌린다.
트랜잭션을 커밋하면 수정 사항을 문서를 편집할 때 변경 사항을 저장하는 것과 비슷하게 데이터베이스에 반영되며, 롤백은 변경 사항을 저장하지 않고 편집 세션을 중단하는 것과 비슷하다. 커밋한 트랜잭션은 롤백으로 다시 돌릴 수 없다.
트랜잭션의 연산은 데이터베이스에 모두 반영되든지 아니면 전혀 반영되지 않아야하고 하나라도 오류가 나면 rollback해야한다. 이는 Atomic을 띈다고 볼 수 있다. 또, 각 연산은 서로를 방해할수도, 방해받지도 못한다 이 점에서 Isolation하다고 볼 수 있다
BEGIN TRANSACTION명령어를 호출하고 실행할 명령어들을 작성 한 뒤 COMMIT명령어를 사용해주면된다.
4. Integrity Constraints
Intergrity Constraint는 권한이 있는 사용자가 데이터베이스를 변경할 때 데이터 일관성이 손상되지 않도록 보장한다. 이 데이터베이스에 대한 우발적인 손상을 막는다.
예를 들어 전화번호가 없으면 튜플을 추가할수없거나 시급은 일정금액을 넘어야하는 경우가 있다. 닉네임은 같을 수 없거나 null이면 안된다는 상황도 된다.
이런 Intergrity Constraint은 일반적으로 데이터베이스 스키마 디자인 과정에서 확인되고, 관계를 생성하는 데 사용되는 create table 명령의 일부로 선언된다.
Constraints on a Single Relation

- not null : null이 오지 못하게 제한. 보통 creat table할때 선언됨.
- Primary key : 하나 이상의 열로 구성될 수 있으며 자동으로 null를 허용하지 않는다. 이는 외래 키(Foreign key)의 참조 대상이 되기 적합하다.
- unique : attribute들이 super key를 형성한다고 생각하여 모든 튜플이 같은 데이터를 방지한다. 하지만 이는 null 값을 가질 수 있다.
- check(P) : check는 각 attribute에게 제한을 건다. 연산자로는 비교 연산자와 논리 연산자를 사용할 수있다.
Referential Integrity
데이터베이스에서 하나의 테이블의 attribute 값이 다른 테이블의 attribute 값과 연관된 경우, 데이터 무결성을 유지하기 위한 제약 조건을 설정해야 한다. 즉, Referential integrity를 유지해야한다.
이를 위해서 우리는 foreign key를 이용한다. 이는 하나의 테이블에서 다른 테이블의 primary key와 연결되는 속성이다. 이때 foreign key와 primary key가 일치해야 무결성을 보장할 수 있다. attribute수와 데이터 유형이 동일해야한다.
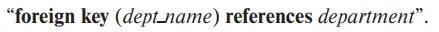
따라서, 참조하는 테이블의 데이터가 변경될 때는, 참조되는 테이블의 데이터도 함께 업데이트되어야한다. 이를 참조 무결성이라고 하고 참조 무결성을 유지하기 위해서는 데이터베이스에서 외래키 제약 조건을 설정해야 한다.
앞에서는 Intergrity 를 위반하면 rollback해야했다. 하지만 외래키는 참조되는 relation에서 변경된 데이터가 있을 때 시스템이 참조하는 튜플을 변경하는 기능을 제공한다.

위의 쿼리문처럼 cascade절을 사용하면 참조된 relation에서 delete나 update가 일어날때 연관된 다른 relation도 그 정보를 반영한다.
cascade 대신에 set null이나 set default를 넣어 참조된 relation에서 delete나 update가 일어날때 null로 채워지거나 defalut값으로 채워지게 성절할 수도 있다.

이것은 나와 부모의 정보를 저장하는 쿼리이다.만약 최초의 조상의 정보가 삽입되었다면 그 사람의 부모정보는 person table에 존재하지 않을것이다.
이는 자기자신을 참조하고 있기 때문에 뭔하는 정보가 들어있지 않을 수도 있다. 이럴때는 null로 채우고 나중에 채우는 방법이 있지만 not null조건이 있다면 이 또한 수행하지 못한다.
Complex Check Conditions and Assertions

check절의 술어 부분은 서브쿼리가 올 수 있다. 이는 time_slot에 있는 id와 각 튜플의 id가 같은지 확인한다. 이는 튜플이 삽입되거나 수정될 때뿐만 아니라 time slot 관계가 변경될 때(이 경우 time slot 관계의 튜플이 삭제되거나 수정될 때)도 확인해야 한다.
이는 데이터의 무결성을 보장하고자 할 때 유용하지만 테스트하는 데 드는 비용이 크게 증가할 수 있다.

assertion은 데이터베이스가 항상 만족해야하는 조건을 나타내는 술어이다. 우리는 이를 통해 “우리는 한 교수님은 한 time에 한과목만 맡을 수 있다” 와 같은 조건을 수행할 수 있다. 이는 복잡한 조건을 표현하는데에 매우 유용하다.
5. SQL Data Types and Schemas
Date and Time Types in SQL
- date : ‘2005-7-27’
- time : '09:00:30’
- timestamp : '2005-7-27 09:00:30.75’ , 날짜와 시간의 조합
- interval : 날짜들끼리 차를 구하면 간격값이 표시됨
Large-Object Types
사진, 비디오 와 같은 용량이 큰 응용프로그램도 데이터베이스에 저장할 수 있다. 쿼리는 객체 그 자체가 아닌 포인터를 반환한다.
User-Defined Types

create type문을 이용하면 사용자 정의 타입을 만들 수 있다. 이렇게 정의된 타입은 다른 타입과 동일하게 쓰인다.

타입 뿐만 아니라 create domain을 이용하면 domain도 지정할 수 있다. 이는 C의 구조체와 비슷한 형태이다. type과 비슷하게 보일 수 있지만 이는 domain이기 때문에 constraint를 포함한다. 이는 DB에서 정의된 제약조건PRIMARY KEY, UNIQUE , CHECK, FOREIGN KEY, NOT NULL을 이용하여 나타낸다.
6. Index Definition in SQL
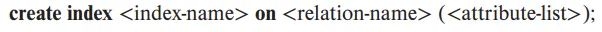
index는 매번 쿼리를 탐색하지 않고 원하는 데이터를 찾을 수 있도록 특정 attribute와 그의 주소를 저장해준다. 이는 메모리에 저장되기 때문에 많이 사용되는 attribute인지 확인하고 사용해야한다.
7. Authorization
우리는 유저에게 DB의 권한을 부여할 수 있다. 권한의 종류는 다음과 같다.
- select (Read)
- Insert
- Update
- Delete
이러한 권한들은 여러가지로 조합하여 부여할 수 있다.
Granting and Revoking of Privileges

grant를 이용하면 권한을 부여할 수 있다. 부여할 권한, 부여될 테이블, 부여받을 유저를 입력하면 된다. 보통 유저의 정보는 ID가 입력된다. 여기에 public을 입력하면 이는 모든 사용자에게 권한을 허용한다는 의미이다.
모든 권한을 부여하고싶을 때는 4개의 권한을 모두 명시해도되지만 all privileges라고 명시하면 모든 권한이 허용된다.
여기서 주의할 점은 뷰에 대한 권한을 부여한다해서 relation에도 권한이 부여되지는 않다는 것이다. 또, 권한을 부여해주는 사람은 이미 그 권한을 가지고 있는 사람이어야한다.
권한을 받은 relaion으로 받은 view에 대해서도 같은 권한을 가지고 있다. 하지만 이는 view에게만 권한설정을 바꿀 수 있다.

revoke를 이용하면 권한을 뺏을 수 있다. 명령어의 사용은 grant와 동일하다. 보통 권한을 부여한 사용자가 해달 권한을 뺏을 수 있다.
동일한 권한이 서로 다른 부여자에 의해 동일한 사용자에게 두 번 부여된 경우, 사용자는 한번의 해지 후에도 권한을 유지할 수 있다. 따라서 중복 부여를 조심해야한다.
또, relaion에 대한 권한이 해지되면 종속된 다른 데이터들의 권한도 해지된다.
Roles
role이란 user들의 그룹이라고 이해할 수 있다.

creat role를 이용하여 role를 만든다.
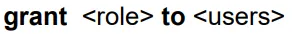
grant를 이용하여 role에 user를 추가한다.
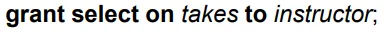
그 후 role에 권한을 부여해주면, role의 모든 user들이 권한을 얻는다
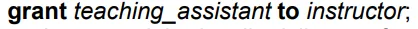
role에게 role을 부여해주는 것도 가능하다. 이렇게 되면 instructor은 teaching_assistant에 포함되게 되고 모든 권한을 부여받는다.
Authorization on Views
View에 대한 권한 부여는 Relation에 대한 권한 부여와 유사하다. 하지만 View에 대한 권한을 부여하려면, View의 기반이 되는 Relation에 대한 권한이 필요하다. View가 여러 개의 Relation을 참조하면, 이러한 Relation 중 하나에 대한 권한이라도 있어야 View에 대한 권한을 부여할 수 있다. ]
또, 권한이 있는 view로 새로운 view를 만든다면 권한도 상속된다.

geo_staff는 instruct에 대한 권한이 없다. 그래서 지질학과 교수님들만 모아놓은 view를 만들어 그 view의 권한을 geo_staff에게 부여해줬다.
하지만 사실은 geo_staff은 애초에 instruct에 대한 권한이 없기 때문에 view를 만들지도 못하고 따라서 select 권환을 부여받는 것도 말이 안된다.
'학부 내용 정리 > [ 3-1 ] 데이터베이스' 카테고리의 다른 글
| [ DB ] Chapter 3. Introduction to SQL (0) | 2025.03.28 |
|---|---|
| [ DB ] Chapter 2. Introduction to Relational Model (0) | 2024.03.08 |
| [ DB ] Chapter 1. Introduction to DB (0) | 2024.03.08 |